We introduce a framework for uncertainty quantification of generative video models and present Semantically-Quantifying Uncertainty with Bayesian Entropy Decomposition (S-QUBED), a method for disentangling aleatoric uncertainty from epistemic uncertainty.
Generative video models demonstrate impressive text-to-video capabilities, spurring widespread adoption in many real-world applications. However, like large language models (LLMs), video generation models tend to hallucinate, producing plausible videos even when they are factually wrong. Although uncertainty quantification (UQ) of LLMs has been extensively studied in prior work, no UQ method for video models exists, raising critical safety concerns. To our knowledge, this paper represents the first work towards quantifying the uncertainty of video models. We present a framework for uncertainty quantification of generative video models, consisting of: (i) a metric for evaluating the calibration of video models based on robust rank correlation estimation with no stringent modeling assumptions; (ii) a black-box UQ method for video models (termed S-QUBED), which leverages latent modeling to rigorously decompose predictive uncertainty into its aleatoric and epistemic components; and (iii) a UQ dataset to facilitate benchmarking calibration in video models, which will be released after the review process. By conditioning the generation task in the latent space, we disentangle uncertainty arising due to vague task specifications from that arising from lack of knowledge. Through extensive experiments on benchmark video datasets, we demonstrate that S-QUBED computes calibrated total uncertainty estimates that are negatively correlated with the task accuracy and effectively computes the aleatoric and epistemic constituents.
Given a text prompt  , S-QUBED quantifies the
uncertainty
of video generation models via latent modeling.
First, our method generates n latent prompts consistent with
in line with the
prompt refinement used by video models, modeling the aleatoric uncertainty as the entropy of the
distribution over latent prompts.
Then, for each latent prompt, S-QUBED generates m videos,
modeling the
epistemic uncertainty as the conditional entropy of the distribution over generated videos.
Finally,
aggregating the two types of uncertainties yields the total predictive uncertainty.
, S-QUBED quantifies the
uncertainty
of video generation models via latent modeling.
First, our method generates n latent prompts consistent with
in line with the
prompt refinement used by video models, modeling the aleatoric uncertainty as the entropy of the
distribution over latent prompts.
Then, for each latent prompt, S-QUBED generates m videos,
modeling the
epistemic uncertainty as the conditional entropy of the distribution over generated videos.
Finally,
aggregating the two types of uncertainties yields the total predictive uncertainty.
Aleatoric uncertainty encompasses irreducible randomness from the vagueness (lack of sufficient specificity) of the conditioning inputs, e.g., “generate a video of a cat doing something.” In video generation, vagueness in the input prompt increases the randomness of the generation of latent prompts.
We show examples of different levels of aleatoric uncertainty for different generation tasks:
Generate a video of a cat doing something.
A close-up shot of a tabby cat napping on a couch with lots of sunlight coming in through the windows.
Epistemic uncertainty represents the measure of doubt associated with a lack of knowledge, which generally results from insufficient training data. Although the generated videos are all conditioned on semantically-consistent latent variables, the generated videos might be semantically-inconsistent, since the video model has not been trained on videos of lions.
We show examples of different levels of epistemic uncertainty and the ground-truth (GT) for different generation tasks:
Generate a video of Violet Evergarden walking with an umbrella.
Generate a video of Luffy walking with an umbrella.
Widely-used calibration metrics, such as the expected calibration error (ECE) and maximum calibration metrics (MCE) apply only to evaluation settings with discrete ground-truth answers and errors, e.g., with multiple-choice questions, making them unsuitable in video generation tasks with real-valued task errors. Consequently, we propose appropriate metrics for evaluating the calibration of the uncertainty estimates of video models. Specifically, we examine the Kendall rank correlation (Kendall's τ) between the video model's uncertainty estimates and an applicable accuracy metric, which captures the degree of monotonicity between uncertainty and accuracy. Here, we show the statistical significance of the Kendall rank correlation between human-annotated uncertainty and widely-used perceptual metrics: structural similarity index measure (SSIM), peak signal-to-noise ration (PSNR), and learned perceptual image patch similarity (LPIPS). We find that the CLIP cosine similarity score provides the most significant correlation.
We visualize ground-truth and generated videos at low, medium, and high human-labeled uncertainty values (from left to right).
A close up of a moon with holes in it.
A blender filled with sliced oranges on a counter.
A video game screen showing a list of items.
We examine the calibration of our uncertainty estimates in VidGen-1M and Panda-70M, using the CLIP
score accuracy metric given its effectiveness in assessing calibration.
We first compute the total predictive uncertainty associated with each video task using S-QUBED,
and then evaluate the Kendall rank correlation. We define the accuracy of each task as the mean CLIP
score across all generated videos for that task.
The results indicate a statistically significant
correlation between accuracy and uncertainty for both datasets, signified by the small p-values.
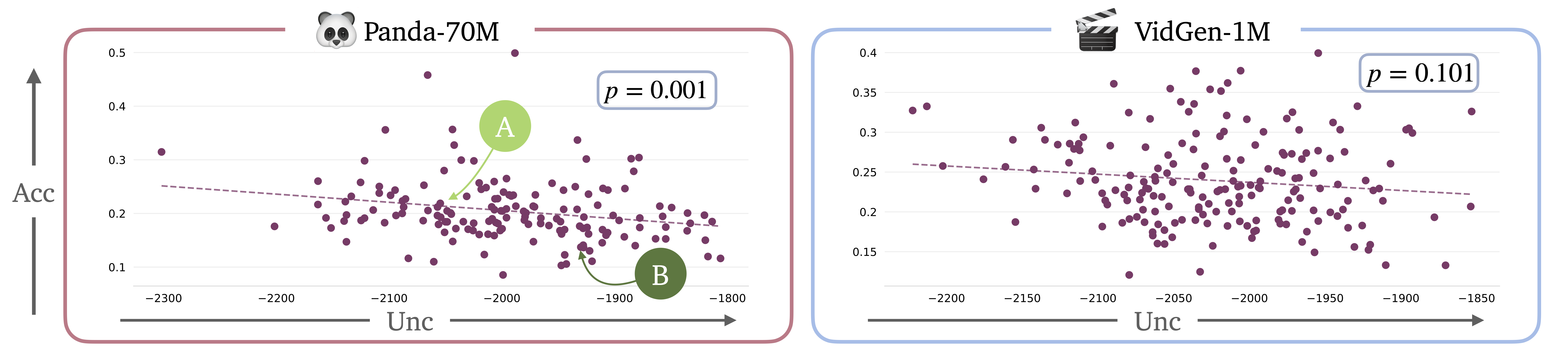
We visualize two samples with different total uncertainty from Panda-70M, denoted by A and B.
A man is sitting... laboratory and talking to the camera... blue shirt... a jar of peanuts...
A woman is cooking food in a white pot on a gas stove.
We examine the performance of S-QUBED in decomposing total uncertainty into aleatoric and epistemic
uncertainty.
To effectively assess calibration of aleatoric uncertainty, we consider a subset of each dataset
where
the epistemic uncertainty is almost zero and compute the rank correlation between the aleatoric
uncertainty of these samples and the CLIP score.
Likewise, to evaluate calibration of epistemic uncertainty, we compute the rank correlation between
the
epistemic uncertainty and the CLIP score for samples with relatively zero aleatoric uncertainty. In
practice, we select samples with the lowest aleatoric or epistemic uncertainty, accordingly.
In Panda-70M, we find that aleatoric and epistemic uncertainty are negatively correlated with
accuracy
at the 94.5% and 98.3% confidence level.
Similarly, in VidGen-1M, we observe a statistically significant negative correlation between
aleatoric and
epistemic
uncertainty and the accuracy at the 92.3% and 91.7%, respectively, demonstrating the effectiveness
of S-QUBED in disentangling aleatoric uncertainty from epistemic uncertainty.

We show ground-truth and generated videos at low, medium, and high aleatoric and epistemic uncertainty (from left to right).
A black cat with blue eyes is sitting on a blue carpet looking at the camera.
There is a soccer game happening in a stadium and the fans are waving flags and cheering.
A display of pictures and information about a school.
@misc{mei2025confidentvideomodelsempowering,
title={How Confident are Video Models? Empowering Video Models to Express their Uncertainty},
author={Zhiting Mei and Ola Shorinwa and Anirudha Majumdar},
year={2025},
eprint={2510.02571},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.02571},
}
